
Tags
Src:https://support.google.com/webmasters/answer/174992?hl=en
Overview
If you’re running an AJAX application with content that you’d like to appear in search results, we have a new process that, when implemented, can help Google (and potentially other search engines) crawl and index your content. Historically, AJAX applications have been difficult for search engines to process because AJAX content is produced dynamically by the browser and thus not visible to crawlers. While there are existing methods for dealing with this problem, they involve regular manual maintenance to keep the content up-to-date.
In contrast, the scheme below helps search engines to scalably crawl and index your content, and it helps webmasters keep the indexed content current without ongoing manual effort. If your AJAX application adopts this scheme, its content can show up in search results. The scheme works as follows:
- The site adopts the AJAX crawling scheme.
- Your server provides an HTML snapshot for each AJAX URL, which is the content a user (with a browser) sees. An AJAX URL is a URL containing a hash fragment, e.g.,
www.example.com/index.html#mystate, where#mystateis the hash fragment. An HTML snapshot is all the content that appears on the page after the JavaScript has been executed. - The search engine indexes the HTML snapshot and serves your original AJAX URLs in its search results.
In order to make this work, the application must use a specific syntax in the AJAX URLs (let’s call them “pretty URLs;” you’ll see why in the following sections). The search engine crawler will temporarily modify these “pretty URLs” into “ugly URLs” and request those from your server. This request for an “ugly URL” indicates to the server that it should not return the regular web page it would give to a browser, but instead an HTML snapshot. When the crawler has obtained the content for the modified ugly URL, it indexes its content, then displays the original pretty URL in the search results. In other words, end users will always see the pretty URL containing a hash fragment. The following diagram summarizes the agreement:
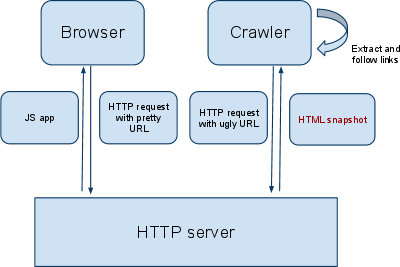
For more information, see the AJAX crawling FAQ and the developer documentation.
Step-by-step guide
The first step to getting your AJAX site indexed is to indicate to the crawler that your site supports the AJAX crawling scheme. The way to do this is to use a special token in your hash fragments (that is, everything after the #sign in a URL). Hash fragments that represent unique page states must begin with an exclamation mark. For example, if your AJAX app contains a URL like this:
www.example.com/ajax.html#mystate
it should now become this:
www.example.com/ajax.html#!mystate
When your site adopts the scheme, your site will be considered “AJAX crawlable.” This means that the crawler will see the content of your app if your site supplies HTML snapshots.
Suppose you would like to get www.example.com/index.html#!mystate indexed. Your part of the agreement is to provide the crawler with an HTML snapshot of this URL, so that the crawler sees the content. How will your server know when to return an HTML snapshot instead of a regular page? The answer lies in the URL that is requested by the crawler: the crawler will modify each AJAX URL such aswww.example.com/ajax.html#!mystate to temporarily become www.example.com/ajax.html?_escaped_fragment_=mystate. We refer to the former as a “pretty URL” and the latter as an “ugly URL”.
This is important for two reasons:
- Hash fragments are never (by specification) sent to the server as part of an HTTP request. In other words, the crawler needs some way to let your server know that it wants the content for the URL
www.example.com/ajax.html#!mystate. - Your server, on the other hand, needs to know that it has to return an HTML snapshot, rather than the normal page sent to the browser. Remember: an HTML snapshot is all the content that appears on the page after the JavaScript has been executed. Your server’s end of the agreement is to return the HTML snapshot for http://www.example.com/index.html#!mystate (that is, the original URL) to the crawler.
Note: The crawler escapes certain characters in the fragment during the transformation. To retrieve the original fragment, make sure to unescape all %XX characters in the fragment (for example, %26 should become ‘&’, %20 should become a space, %23 should become #, and %25 should become %).
Now that you have your original URL back and you know what content the crawler is requesting, you need to produce an HTML snapshot. Here are some ways to do this:
- If a lot of your content is produced with JavaScript, you may want to use a headless browser such as HtmlUnitto obtain the HTML snapshot. Alternatively, you can use a different tool such as crawljax or watij.com.
- If much of your content is produced with a server-side technology such as PHP or ASP.NET, you can use your existing code and replace only the JavaScript portions of your web page with static or server-side created HTML.
- You can create a static version of your pages offline. For example, many applications draw content from a database that is then rendered by the browser. Instead, you may create a separate HTML page for each AJAX URL. This is similar to Google’s previous Hijax recommendation.
Some of your pages may not have hash fragments. For example, you probably want your home page to bewww.example.com, rather than www.example.com#!home. For this reason, we have a special provision for pages without hash fragments.
In order to get pages without hash fragments indexed, you include a special meta tag in the head of the HTML of your page. Important: Make sure you use this solution only for pages that include Ajax content. Adding this to non-Ajax pages creates no benefit and puts extra load on your servers and Google’s. The meta tag takes the following form:
<meta name="fragment" content="!">
This tag indicates to the crawler that it should crawl the ugly version of this URL. As per the above agreement, the crawler will temporarily map the pretty URL to the corresponding ugly URL. In other words, if you place <meta name="fragment" content="!"> into the page http://www.example.com, the crawler will temporarily map this URL towww.example.com?_escaped_fragment_= and will request this from your server. Your server should then return the HTML snapshot corresponding to www.example.com.
Please note that one important restriction applies to this meta tag: the only valid content is "!". In other words, the meta tag will always take the exact form: <meta name="fragment" content="!">, which indicates an empty hash fragment, but a page with AJAX content.
Crawlers use Sitemaps to complement their discovery crawl. Your Sitemap should include the version of your URLs that you’d prefer to have displayed in search results, so in most cases it would behttp://example.com/ajax.html#!foo=123 (rather than http://example.com/ajax.html?_escaped_fragment_=foo=123), unless you have an entry page to your site—such as your homepage—that you would like displayed in search results without the #!. For instance, if you want search results to displayhttp://example.com/, include http://example.com/ in your Sitemap with <meta name="fragment" content="!"> in the <head> of your document. For more information, check out our additional articles onSitemaps.
